

LLM은 사람과 끊기지 않는 지적인 대화를 할 정도로 “똑똑해” 보입니다. 챗봇이 내놓는 답이 ‘정답’이라고 생각하기도 하지만, 사실 LLM은 ‘정답을 찾는 검색’이 아니라, 주어진 문맥에서 ‘다음 토큰(next token)’을 가장 그럴듯하게 이어 붙이는 확률 모델입니다.
이 차이를 이해하지 못하면, PoC에서는 그럴듯했던 결과가 프로덕션에서 곧바로 환각(hallucination), 재현성 문제(답변 변동), 데이터 통제·보안·감사 이슈로 바뀝니다. 반대로 작동 원리를 정확히 이해하면, 팀의 대화가 “모델 고르기”에서 “운영할 수 있는 시스템 설계”로 옮겨갑니다.
토큰이 운영의 핵심인 이유는 간단합니다. LLM을 실제 서비스로 올리는 순간, 대부분의 문제가 결국 “토큰”으로 환산되기 때문입니다. 입력(prompt) 토큰은 시스템 프롬프트·대화 히스토리·RAG 근거·툴 결과까지 모두 합쳐지며, 이 합이 커질수록 비용과 지연이 함께 증가합니다. 동시에 컨텍스트 윈도우는 토큰 단위로 제한되므로, 근거를 최대한 많이 넣는 전략은 응답 시간이 길어질뿐더러, 답변 내용의 차이가 더 벌어지고 때로는 처리 불가로 이어집니다. 마지막으로 출력(completion) 토큰은 답변 길이와 변동성을 통해 재현성과 운영 안정성을 좌우합니다. 그래서 “모델을 무엇으로 고를지”보다 “토큰을 어떻게 배분·제어·관측할지”가 곧 운영할 수 있는 GenAI의 성패를 결정합니다.
개요
이 글에서 다룰 내용입니다
- 운영 문제: 환각·답변 변동·비용/지연이 커지는 이유는 무엇인가
- 원인: LLM의 “다음 토큰 예측” 구조와 컨텍스트 윈도우 제약이 토큰 예산을 어떻게 흔들고, 어떤 한계를 만드는가
- 해결: 토큰 예산 분할, 근거 선별(청킹/재정렬/중복 제거/압축), 디코딩(온도·top-k/top-p) 및 토큰 로깅으로 비용 폭증과 품질 흔들림을 막는 운영 방법
이 글은 이런 분들께 도움이 됩니다
- LLM 도입 비용이 예상보다 빠르게 늘어나는 팀
프롬프트·RAG 근거·출력 길이가 어떻게 토큰으로 비용과 지연을 키우는지 원인을 분해하고, 토큰 예산 관점에서 운영 기준을 세우고 싶은 분 - RAG를 붙였는데도 답변 품질이 들쭉날쭉한 조직
컨텍스트 윈도우 한도 때문에 “많이 넣기”가 왜 실패하는지 이해하고, 근거로 무엇을 넣고 무엇을 버릴지 기준을 만들고 싶은 분 - 정책/규정/정답형 업무에 LLM을 적용하려는 실무 리더
샘플링·디코딩 설정이 재현성과 변동성에 미치는 영향을 이해하고, 일관된 답변을 위한 운영 정책과 토큰 로깅 기반 관측 체계를 갖추고 싶은 분
1) LLM 작동 원리 한 줄 요약: “다음 토큰 예측기”
LLM의 생성은 본질적으로 단순합니다. 지금까지의 입력을 보고, 다음에 올 토큰(token)을 확률적으로 예측합니다. 그리고 이 과정을 토큰 단위로 반복하면서 문장을 완성합니다.
여기서 중요한 점은 두 가지입니다.
- LLM은 “정답”을 조회해 꺼내는 방식이 아닙니다. 매 순간 확률적으로 가장 그럴듯한 다음 토큰을 선택합니다.
- LLM의 강점은 “패턴 학습”이지 “사실 보장”이 아닙니다. 이 구조적 특성이 곧 환각과 재현성 문제로 이어집니다.
아래의 내용을 통해 LLM의 작동 원리인 “다음 토큰 예측”이 실제로 어떻게 구현되는지를 살펴 보겠습니다.

토큰이란?
토큰은 LLM이 텍스트를 이해하고 생성할 때 사용하는 최소 계산 단위입니다. 중요한 점은 토큰이 항상 “단어”가 아니라는 것입니다. 모델은 문장을 단어 전체로 처리하기보다 단어 조각(서브워드; subword), 숫자, 구두점, 공백을 포함한 문자열 조각으로 분해해 다룹니다. 예를 들어 영어 단어 unbelievable은 모델에 따라 un + believ + able처럼 여러 토큰으로 쪼개질 수 있고, 긴 숫자나 코드 문자열(예: 2026-01-26, SELECT * FROM...)도 기호와 조각 단위로 분해되어 토큰 수가 빠르게 늘어날 수 있습니다. 한국어도 마찬가지로, “생성형AI”처럼 붙여 쓴 표현과 “생성형 AI”처럼 띄어 쓴 표현은 토큰화 결과가 달라질 수 있어, 겉보기에는 글자 수가 비슷해도 토큰 수는 달라질 수 있습니다.

LLM이 단어를 조각(서브워드; subword)으로 쪼개는 이유는, 언어에 등장하는 단어가 사실상 무한하기 때문입니다. 단어를 통째로 토큰화하면 신조어·오타·사내 용어 같은 “사전에 없는 단어(OOV; Out-Of-Vocabulary)”를 처리하지 못하고, 어휘가 커질수록 학습·추론 비용이 급증합니다. 반면 서브워드 토큰은 제한된 토큰 목록으로도 단어를 조합해 표현할 수 있어, 처음 보는 단어도 최소한으로 분해해 읽고, 문맥 속에서 의미를 추정할 수 있습니다.
이러한 토큰 수는 모델 호출 비용과 지연시간, 그리고 한 번에 넣을 수 있는 입력량에 직접적인 영향을 줍니다. 따라서 RAG처럼 문서 근거를 프롬프트에 주입하는 구조에서는 “얼마나 많은 문서를 넣을 수 있나”가 결국 남아 있는 토큰 예산(token budget)의 문제로 바뀝니다.

2) 토큰이 왜 품질에 영향을 주는가
LLM은 텍스트를 그대로 처리하지 않습니다. 입력 문장은 먼저 토큰 단위로 쪼개지고, 텍스트 임베딩(text embedding) 작업을 통해 각 토큰을 모델이 이해하는 벡터, 즉 숫자로 바뀝니다.
이 단계는 단순한 전처리가 아닌 비용·지연·품질을 좌우하는 실무 변수이며, 그 이유는 다음과 같습니다.
임베딩이란?
임베딩은 데이터를 벡터(좌표)로 바꾸는 작업, 그리고 텍스트 임베딩은 일반적인 문서의 텍스트를 모델이 이해하는 벡터로 변경하는 작업입니다. 이 벡터에는 토큰의 의미와 문맥적 특징이 담기며, 해당 임베딩들 사이의 관계를 계산해 LLM은 “지금 문맥에서 상대적으로 가장 적합한 정보”를 찾습니다. 즉, 임베딩은 LLM이 글자를 그대로 읽는 대신 수치화된 의미 공간에서 이해하고 추론하게 만드는 출발점입니다.
1) 비용과 지연시간이 ‘토큰 수’에 의해 결정됩니다
대부분의 LLM API는 입력 토큰 + 출력 토큰을 기준으로 사용량/비용을 계산합니다. 즉, 같은 요청이라도 토큰이 늘면 비용과 응답 시간이 함께 늘어날 가능성이 큽니다.
2) 컨텍스트 윈도우는 “토큰 단위”로 제한됩니다
컨텍스트 윈도우(context window)는 모델이 한 번에 고려할 수 있는 텍스트 양(일종의 작업 메모리)이며, 토큰 기준으로 측정됩니다. 입력이 이 윈도우를 넘으면 일부 내용이 잘리거나(또는 요약/압축되어) 품질이 급격히 흔들릴 수 있어, 토큰 예산 전략과 밀접하게 연관되어 있습니다.

3) 출력 품질은 “토큰 예산” 설계에서 갈립니다
RAG에서 하는 일
사용자가 답변을 요구하면, RAG에서 ‘근거가 될 만한 문서 조각(스니펫(snippet)/청크(chunk))을 찾습니다. 즉, LLM이 답을 “검색”하는 게 아니라, LLM이 답을 만들 때 인용할 근거를 검색합니다. 그다음, 검색해 가져온 근거(문서 스니펫)를 LLM API로 보내는 최종 프롬프트(augmented prompt)에 넣습니다.
컨텍스트 윈도우/토큰 예산 제약과 결과
텍스트 윈도우는 LLM이 한 번의 요청에서 동시에 읽고 참고할 수 있는 입력의 최대량입니다. 중요한 점은 이 한도가 사용자 질문만으로 채워지는 게 아니라, 시스템 프롬프트(규칙/역할), 대화 히스토리, RAG로 가져온 근거 스니펫, 툴 호출 결과까지 모두 합쳐진다는 것입니다. 즉 RAG 설계에서 “근거를 얼마나 넣을 수 있냐”라는 질문은 곧 “전체 토큰 예산(token budget) 중 근거에 몇 토큰을 배정할 것인가”로 바뀝니다. 컨텍스트 윈도우를 넘으면 입력이 중간에 잘릴 수 있고 토큰이 모자라면 요청이 실패할 수 있습니다. 특히 LLM이 찾을 수 있는 근거가 잘리면 답변 품질이 급격히 흔들립니다.
따라서 컨텍스트가 길다고 무조건 좋은 것이 아닙니다. 관련 없는 스니펫이 섞이면 모델이 중요한 근거를 놓치거나 불필요한 내용을 참고할 수 있어, 결과적으로 “많이 넣는 것”보다 “정확히 골라 넣는 것”이 더 중요해집니다.
기업 환경에서 “프롬프트를 길게 쓰면 더 정확해질 것”이라는 전략은 종종 더 낮은 품질의 답변으로 이어집니다. 이 현상을 더 깊이 이해하기 위해 트랜스포머에 대해 살펴 보겠습니다.
토큰 예산 3개로 나누세요
(1) 시스템/정책 지시문, (2) 근거 컨텍스트(RAG), (3) 사용자 질문 + 모델 답변을 위한 여유 출력 토큰을 사전에 배정하세요. 컨텍스트만 꽉 채우면 답변이 짧아지거나 잘리며, 품질이 떨어집니다.
예시: 토큰 예산을 3분할하면 이렇게 잡습니다
컨텍스트 윈도우가 8,000 토큰인 모델을 가정하면, 한 요청의 토큰 예산을 아래처럼 “구역”으로 나눠 운영할 수 있습니다.
(1) 시스템/정책 지시문: 약 800 토큰 (10%)
(2) 근거 컨텍스트(RAG): 약 4,800 토큰 (60%)
(3) 사용자 질문 + 출력 여유: 약 2,400 토큰 (30%)
예: 사용자 질문 400 토큰 + 최대 출력 2,000 토큰
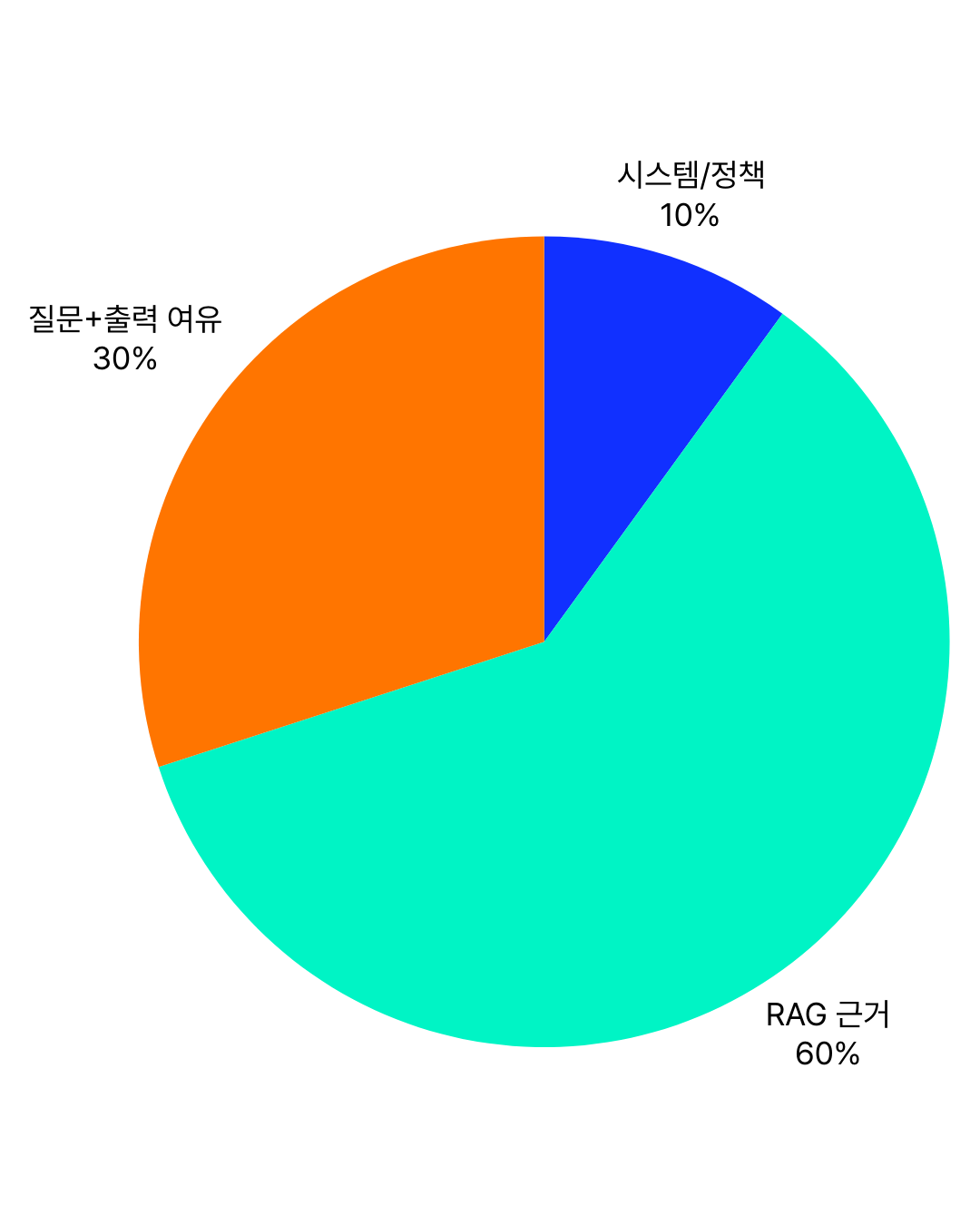
핵심은 (2) 근거만 최대치로 채우지 않고, (3) 출력 여유를 명시적으로 남겨두는 것입니다. 근거를 과도하게 넣으면 모델이 답변을 충분히 생성하지 못해 출력이 짧아지거나 잘리고, 결과적으로 품질이 떨어집니다.
3) 트랜스포머와 셀프 어텐션: 문맥을 계산하는 방식
트랜스포머란, 토큰들을 받아 셀프 어텐션(자기-어텐션; self-attention)으로 토큰 간 관계를 계산해 문맥 표현을 만들고, 그 결과를 기반으로 다음 토큰 확률을 예측하게 하는 LLM의 핵심 신경망 아키텍처입니다. 트랜스포머의 핵심 메커니즘인 셀프 어텐션은 토큰 간 관계를 계산해 “지금 답을 만들 때 중요한 단어”에 더 집중하도록 설계되어 있습니다.
그렇다면 문맥을 이렇게 잘 계산하는데, 왜 입력을 길게 넣으면 오히려 성능이 떨어질까요?
그것은 셀프 어텐션이 “모든 토큰을 동일하게” 보지 않기 때문입니다. 트랜스포머 기반 LLM은 셀프 어텐션으로 입력 토큰 간의 관련도를 계산해, 각 토큰이 “문맥을 반영한 표현”이 되도록 갱신합니다. 문제는 이 메커니즘이 “입력을 많이 넣을수록 무조건 잘 이해한다”는 뜻이 아니라는 점입니다. RAG에서 근거 스니펫을 과도하게 넣으면, 모델은 제한된 컨텍스트 윈도우 안에서 더 많은 토큰에 어텐션을 분산해야 하고, 그 결과 질문에 직접 필요한 핵심 문장(예. 정의/조건/예외/절차)이 주변의 덜 중요한 문장에 묻히기 쉽습니다. 즉, 컨텍스트 윈도우가 아무리 커도 “문서 전체를 그대로 입력하는 방식”이 제일 나은 방법은 아닐 수 있습니다.
결국 출력의 품질은 “얼마나 많이 넣느냐”가 아니라, 트랜스포머가 집중할 수 있도록 무엇을 넣고 무엇을 버릴지에 의해 결정됩니다. 그래서 RAG 파이프라인에서 청킹(chunking), 재정렬(rerank), 중복 제거(dedup), 요약·압축(compression)은 선택 기능이 아니라, 컨텍스트 윈도우라는 제약 아래에서 트랜스포머의 강점을 제대로 쓰기 위한 필수 단계가 됩니다.
이어서 토큰 사용에 영향을 주는 LLM의 출력은 어떻게 결정되는지 살펴 보겠습니다.
4) 프롬프트에서 답변까지: LLM 추론의 기본 절차
LLM의 추론(inference)이란, 학습이 끝난 모델을 실제 서비스에서 호출해 텍스트를 생성하는 실행 과정입니다. 요청이 들어오면 시스템/개발자 프롬프트, 대화 히스토리, RAG 근거 스니펫, 사용자 질문을 합쳐 입력을 구성하고, 이를 토큰화합니다. 트랜스포머는 토큰 간 관계를 계산해 문맥 표현을 만든 뒤 “다음 토큰”의 확률분포를 출력합니다. 모델은 그 분포에서 토큰을 하나 선택해 출력 뒤에 붙이고, 다시 다음 토큰 분포를 계산하는 과정을 반복하며 문장을 완성합니다. 생성은 보통 종료 토큰 생성(모델이 출력을 끝내야 한다고 판단), stop sequence 감지(모델이 특정 문자열이나 패턴을 생성하면 출력을 멈추도록 설정해 두는 외부 종료 규칙), 또는 최대 출력 토큰 수 도달 같은 조건에서 멈춥니다.
정답형 출력을 제어하고 관측하세요
- 정답형 업무는 출력 변동 폭을 줄이세요
불필요한 장문 출력을 제한하려면 최대 출력 토큰을 설정하고, 프롬프트를 “짧고 구조화된 출력(JSON/목록 등)”으로 유도하는 편이 안전합니다. - 관측(Observe)하세요
관측(Observability)의 출발점은 토큰 로깅(token logging), 즉 LLM을 호출할 때마다 그 요청이 사용한 토큰 사용량을 기록하는 것입니다. LLM의 비용과 지연은 대부분 입력과 출력으로 결정되기 때문입니다.
여기서 입력은 사용자 질문만이 아니라 시스템 프롬프트(규칙/역할), 대화 히스토리, RAG로 가져온 근거 스니펫, 툴 호출 결과까지 모두 합친 입력 토큰을 의미합니다. 반대로 출력은 모델이 생성한 답변 길이(출력 토큰)입니다.
따라서 요청 단위로 입력/출력 토큰을 로깅(기록)하면, 비용 증가가 “모델이 비싸서”가 아니라 입력이 길어서인지, 출력이 과도해서인지, 더 나아가 RAG 근거·히스토리·템플릿 중 무엇이 토큰을 잡아먹는지를 정량적으로 분해할 수 있고, 그 결과 최적화 포인트를 빠르게 특정할 수 있습니다.
5) 왜 같은 질문인데 답이 달라지나: 샘플링, 온도, top-k/top-p
샘플링: 다음 토큰을 ‘뽑는’ 방식
LLM은 다음에 올 말을 단 하나로 결정해 꺼내는 것이 아니라, 여러 후보 중에서 고르는 방식으로 문장을 이어갑니다. 가장 그럴듯한 1등 후보만 매번 고르면 답이 항상 비슷해지겠지만, 실제로는 2등·3등 후보도 충분히 자연스러운 경우가 많습니다. 그래서 모델은 후보들 중 하나를 선택하는 방식으로 동작할 수 있는데, 이 과정을 샘플링(sampling)이라고 부릅니다.
디코딩: ‘무엇을 뽑을지’를 정하는 규칙
여기서 한 가지 개념을 더 붙이면, LLM이 “후보 중 무엇을 실제로 뽑을지”를 결정하는 방법 자체를 디코딩(decoding)이라고 합니다. 즉 모델은 단계마다 다음 토큰 후보들과 그 확률/확률분포를 계산해 내놓고, 디코딩은 그 분포를 바탕으로 어떤 토큰을 선택해 출력에 붙일지를 정하는 규칙입니다. 항상 1등 후보만 고르는 방식도 있고(결정적 출력), 여러 후보 중 확률적으로 뽑는 방식도 있는데(샘플링), temperature와 top-k/top-p는 바로 이 디코딩 단계에서 선택의 폭과 무작위성을 조절합니다.
온도·top-k·top-p: 변동성을 조절하는 레버
샘플링 온도(temperature)는 말 그대로 모델의 “모험심(또는 엄격함)”을 조절하는 버튼입니다. 온도를 낮추면 모델이 안전하게 1등 후보에 더 집중해 답변이 더 일정하고 예측 가능해집니다. 반대로 온도를 높이면 모델이 조금 덜 확실한 후보도 시도해 보면서 표현이 더 다양해지고, 때로는 더 창의적인 답이 나오지만, 답변이 들쭉날쭉해질 수 있습니다. 일상 대화나 아이데이션(ideation)에서는 이런 변동성이 도움이 되기도 하지만, 정책/규정/정답형 업무에 그대로 적용하면 운영에서 곧바로 재현성 문제가 발생합니다. 결국 기업 환경에서는 “얼마나 다양하게 답할지”를 상황에 맞게 제어해야 합니다.
샘플링 온도만으로는 후보 선택을 완전히 통제하기 어렵기 때문에, 보통 함께(또는 대안으로) 쓰는 제약이 top-k와 top-p입니다. top-k/top-p는 “선택지의 범위를 어디까지 열어둘지”를 정하는 규칙입니다. top-k는 “상위 k개 후보안에서만 고르는 것”이며, top-p는 “확률이 높은 후보들을 위에서부터 쌓아 올려 누적 확률이 p를 넘는 순간까지의 후보들만 뽑아두고, 그 안에서만 다음 토큰을 고르는 것”입니다. 쉽게 말해, 이 범위를 좁히면 모델이 엉뚱한 후보를 고를 기회가 줄어들어 답이 더 안정적이고, 넓히면 표현의 폭(창의성)은 커지지만 변동도 커집니다.
토큰: 변동·비용·지연이 누적되는 단위
여기서 다시 “토큰”이 중요해집니다. LLM은 문장을 단어 단위로 한 번에 만드는 것이 아니라, 토큰을 한 개씩 선택해 이어 붙이면서 출력을 완성합니다. 샘플링 온도와 top-k/top-p는 “문장 전체”를 조절하는 값처럼 보이지만, 실제로는 단계마다 디코딩 과정에서 ‘다음 토큰’을 어떤 방식으로 뽑을지를 결정합니다. 따라서 출력이 길어질수록(= 생성되는 토큰 수가 많아질수록) 이 선택이 반복되고, 작은 변동이 누적되어 결과가 크게 달라질 수 있습니다. 정답형 업무처럼 일관성이 중요한 경우에는, 디코딩의 변동 폭을 줄여 매 토큰이 안정적으로 이어지도록 설정하는 것이 핵심입니다.
또한 토큰은 비용과도 직결됩니다. 출력이 길어지면 출력 토큰이 증가해 비용과 지연이 함께 커지고, 샘플링 설정이 느슨할수록(샘플링 온도↑, top-p↑) 불필요하게 장황한 답변이 나오는 경향이 생길 수 있습니다. 그러므로 엔터프라이즈에서는 “품질”뿐 아니라 “토큰 예산” 관점에서도 디코딩 정책을 다룹니다. 예를 들어 요약/정책 QA 같은 업무는 낮은 샘플링 온도와 보수적인 top-k/top-p에 더해, 최대 출력 토큰 수(max output tokens)나 간결한 포맷을 함께 걸어 출력 토큰이 과도하게 늘지 않도록 관리합니다.
기업에서는 보통 업무 특성에 따라 운영 정책을 분리합니다. 규정/정책처럼 “틀리면 안 되는” 답변은 샘플링 온도를 낮게, top-k/top-p도 보수적으로 잡아 답이 매번 비슷하게 나오도록 합니다. 반대로 아이디어 발상이나 초안 작성처럼 “다양한 표현이 도움 되는” 작업은 샘플링 온도를 높이고 선택지 범위를 넓혀 더 많은 후보가 나오도록 설정하는 방식이 일반적입니다.
(리마인더) 정답 검색 vs 생성
많은 사람이 LLM을 검색엔진이나 데이터베이스처럼 생각해 “질문하면 어딘가에 저장된 정답을 찾아서 그대로 꺼내준다”고 기대합니다. 여기서 ‘정답을 꺼낸다’라는 것은, 이미 존재하는 문서나 레코드에서 정답을 조회(retrieve)해 반환하는 방식을 뜻합니다. 반면 LLM은 기본적으로 정답 문장을 저장해 두고 가져오는 것이 아니라, 입력 문맥을 바탕으로 다음에 올 토큰을 확률적으로 예측해 문장을 생성(generate)합니다. 따라서 그럴듯하지만, 틀린 답(환각)이 구조적으로 발생할 수 있습니다.
마무리: 결국 토큰을 잡아야 LLM 운영이 잡힙니다
핵심 요약
LLM은 “정답을 검색해 꺼내는 시스템”이 아니라, 문맥에서 다음 토큰을 예측해 생성하는 확률 모델입니다. 그래서 운영에서의 품질·비용·지연 문제는 대부분 토큰 예산으로 환산됩니다. 컨텍스트 윈도우라는 제약 안에서 RAG 근거를 “많이” 넣는 전략은 쉽게 실패하고, 결국 성패는 무엇을 넣고 무엇을 버릴지와 어떻게 관측할지(토큰 로깅)에 달려 있습니다.
즉시 실행 체크리스트
- 토큰 예산을 세 개로 나누세요: (1) 시스템/정책, (2) RAG 근거, (3) 사용자 질문 + 출력 여유(최대 출력 토큰 포함).
- RAG 근거는 ‘많이’가 아니라 ‘정확히’: 청킹 기준을 정하고, 재정렬·중복 제거·요약/압축을 기본값으로 두세요.
- 출력은 구조화하고 제한하세요: 정답형 업무는 최대 출력 토큰과 포맷(JSON/목록)을 걸어 장문·변동을 줄이세요.
- 요청 단위 토큰 로깅을 기본값으로 두세요: 입력/출력 토큰을 기록해 비용 폭증 구간과 품질 흔들림의 원인을 빠르게 분해하세요.
- 디코딩 정책을 업무별로 분리하세요: 정책/규정은 낮은 샘플링 온도와 보수적인 top-k/top-p, 아이데이션은 높은 샘플링 온도와 넓은 선택지로 운영하세요.
Articul8과 운영할 수 있는 로드맵을 함께 세우세요.
PoC를 넘어 프로덕션으로 가려면 “모델 성능”보다 토큰 예산·근거 파이프라인·디코딩·관측이 먼저 정리돼야 합니다. Articul8은 조직의 실제 프롬프트·RAG 구조·로그 데이터를 기준으로 운영할 수 있는 정책을 함께 설계합니다. 지금 겪고 있는 문제를 빠르게 진단하고 해결하고 싶다면 Articul8 1:1 상담을 신청하세요.
함께 읽으면 좋은 콘텐츠
➡️ 왜 기업형 GenAI 프로젝트는 실패하는가: 생성형 AI ROI를 결정하는 데이터 아키텍처 전략
➡️ 기업형 맞춤 AI로 무게중심이 옮겨간 이유: 미라 무라티의 퇴사와 TML의 첫 제품 Tinker가 주는 신호 (Part 1)

뉴스레터에서 만나 보세요.